Beginning Programming in Python
Fall 2019

Agenda
- Strings:
- White space characters
- String operators
- String functions (Find, Split, Join, etc.)
- Slicing
- Immutability
- String comparison
- For loops
- In operator
- Format method
- Formatting numbers
String data type
- Text is represented in programs by the string data type
- A string is an immutable sequence of characters enclosed within quotation marks (") or apostrophes (').
- Example:
- ‘This is a sample sentence.’
- “2x2=4”
String representation
-
Character Encoding
- A string is stored as a sequence of binary numbers, one number per character
- The mapping used to convert characters to numbers and vice-versa is called character encoding
- Python 3 uses Unicode
ord('a')
# Return the Unicode code point for a one-character string.
# Returns 97
chr(97)
# Return a Unicode string of one character with ordinal i
# Returns 'a'whitespace characters
String indexing
greet = "Hello Bob"
print(greet[0])
print(greet[0], greet[2], greet[4])
x = 8
print(greet[x - 2])
print(greet[-1])
print(greet[-3])
print(greet[50]) # Error
print(greet[-(len(greet)+1)]) # This throws an error,
# it implies a character before the start of the string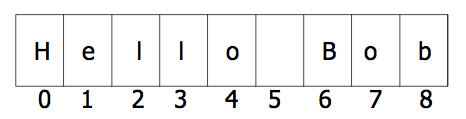
Basic string operators
Concatenation
- Multiplication
- Sorry, no division or subtraction :)
# You can concatenate strings together
s = "Lets" + "add" + "together" + "strings"
print(s) # Note is just puts them one after the other
# (i.e. it doesn't do any whitesppace addition)s = "Hello" * 10
# The multiplication operator allows you to
# make a sequence of strings
print(s) # Note this doesn't work
# What would this even do?
s = "You can't" - "subtract strings"
# Nor does this
s = "You can't" / "divide strings either"String length function
-
The length of a string is given by the "len()" function
s = "A long string"
print(len(s))
# The empty string case
s = ""
print(len(s))
# A String with whitespace character
s = "\t"
print(len(s))Character is just another String
s = "A long string"
# Realise that a character is just another string in Python
# In some languages, like C/C++, individual characters
# are not strings but have a different type, but Python
# treats them as a single character string
print(type(s[0])) # Prints str
print(len(s[0])) # Prints 1
String slicing
# Beyond indexing, you can slice strings to create substrings
greet = "Hello Bob"
print(greet[0:3]) # The 'prefix' substring of the first 3 characters
print(greet[3:3]) # The interval [3, 3) is empty
print(greet[5:8])
# Negative length strings?
print(greet[6:0]) # If the second index occurs before the first index it won't
# throw an error, just make a zero length (empty) string
print(greet[:5]) # This is the same as greet[0:5]
# greet[:n] is called a prefix of greet, where n is in [0, len(greet))
print(greet[5:]) # This is the same as greet[5:9]
# greet[n:] is called a suffix of greet, where n is in [0, len(greet))
print(greet[:]) # This is just the whole string, allowing you to make
# a copy of the stringString immutability
- Strings are immutable
- You cannot edit a string, you can only make new strings by copying them
s = "Strings can't be changed"
# This doesn't work
s[0] = 's'
# To make s lower case you could instead do:
s = 's' + s[1:]
print(s)string comparison
in operator
for loops on strings
Example: removing vowels
Example: search for character
5 minutes break!
Convenience functions
- Find:
- Case changing functions
# Find generalizes the find_character method above to search for substrings
s = "once upon a time there lived, a time"
s2 = "a time"
print(s.find(s2)) # Find first instance of s2 in s
# Prints 10s = "once upon a time there lived"
print(s.upper()) # When you feel like shouting
s = "SHOUTING"
print(s.lower()) # The oppositesplit function
join function
String formatting
'{0}, {1}, {2}'.format('a', 'b', 'c')
# 'a, b, c'
'{}, {}, {}'.format('a', 'b', 'c')
# 'a, b, c'
'{2}, {1}, {0}'.format('a', 'b', 'c')
# 'c, b, a'
'{0}{1}{0}'.format('abra', 'cad')
# 'abracadabra'
string formatting Example
Formatting numbers
Lecture 7 challenge
Questions?
